Klaszterek, gridek
Nemrégen egy konferencián egy külföldi fejlesztőt sikerült elcsípnem, aki egy nagyon érdekes térinformatikai fejlesztésben vett részt (idővel fogok arról is írni, de most ne szaladjunk ennyire előre). A mi szempontunkból lényeges elem az, hogy klaszterizálást végeztek az adott adatokra, amihez open-source szoftverként a SAGA alkalmazást használták.
Mivel a SAGA-hoz korábban nem volt szerencsém, meg is néztem hogy mi mindent tud. Számos geostatisztikai modulja van, így életképes alternatívája lehet egyes - finoman fogalmazva - túlárazott szoftvereknek. Jelen posztban maradjunk viszont a klaszterizálásnál, amire szintén nyújt megoldást a szoftver.
Nagy vonalakban pár szót tehát a klaszterizálásról, mint (geo)statisztikai eszközről.
Alapja a klaszter-analízis, amely a statisztikában honos kifejezés, lényege a homogenizálás, azaz nagyobb adattömbök elemeit minél homogénebb klaszterekbe sorolunk be bizonyos mutatók alapján (pl. távolságelemzés vagy hasonlóságmértékek szerint). Kiváló példa a klaszterek kialakítására a piackutatás.
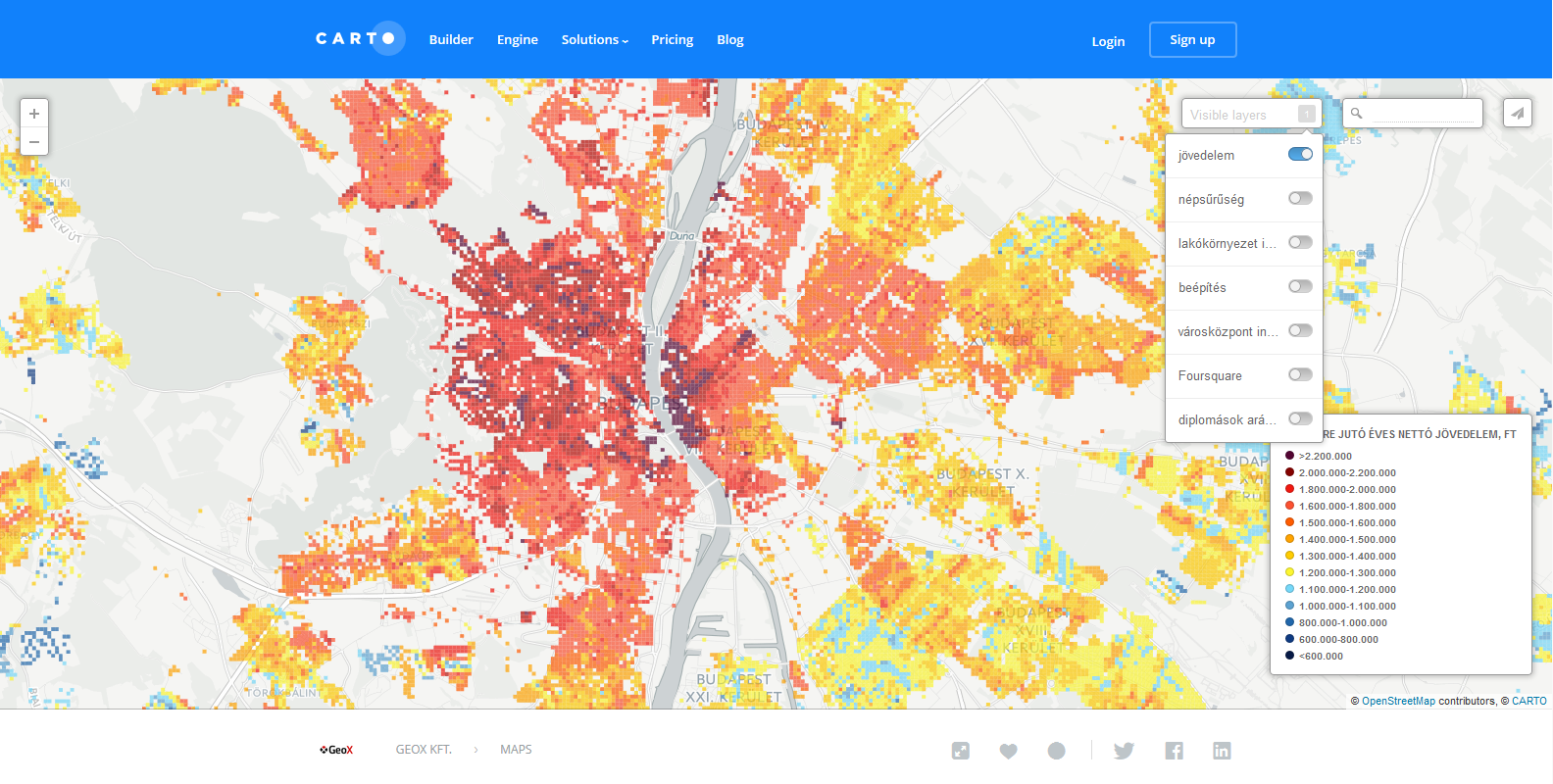
Hogy megkönnyítsük a dolgunkat, ejtsünk pár szót a grid-ekről is. Gridekkel fel tudunk osztani egy területegységet adott nagyságú területegységekre, amelyek nem követnek semmilyen közigazgatási határvonalat, hanem mindentől teljesen függetlenül osztják fel a teret kis egységekre (a terület nagysága akármekkora lehet, pl. 100 méter X 100 méter vagy 5000 méter X 5000 méter, a feldolgozandó adatkörtől függően). Itt van például egy nagyobb terület grides felosztása, de lehetne akár hexagonális kialakítása is a grideknek. Ezekhez a gridekhez aztán adatokat tudunk illeszteni, például egy griden belül hány lakos él, vagy mekkora az átlagos jövedelem az adott griden belül.
Érdemes pozitív példaként megnézni a GeoX 100x100-as adakörét (interaktív térképük elérhető itt), amely szintén gridekhez hozzárendelt adatkörökkel dolgozik: